
The Missing Layer Isn’t Data. It’s Judgment.
We've spent decades building tools that remember everything. What if the next ones actually thought with us?


Foundation Capital recently published a compelling thesis: The next trillion-dollar platforms will be systems of record for decisions, not just objects. If you capture the decision traces (the exceptions, precedents, and cross-system context living in various stacks and people’s heads) you build something incumbents cannot replicate.
I agree with the diagnosis but the prescription feels incomplete.
Decision traces are valuable artifacts of the past. A system that records what happened can explain why a decision was made, but it cannot help you make the next one better.
Without that evolution, AI in the enterprise remains strictly transactional. It becomes a cycle of query, retrieve, and execute. While the machine provides speed, the human remains the sole source of judgment. This means organizations do not get smarter and capability stagnates. The hard problems, specifically the ones that determine who wins, stay exactly as difficult as they were before.
This is why enterprise AI still feels like autocomplete for knowledge work.
These tools will foster better people who make better decisions with advantages that compound over time. That is the advantage that cannot be bought or copied. It is the future that almost no one is currently building toward.
Software vs Intelligence
The architectural inversion
Before addressing judgment, we have to acknowledge a deeper shift in how software is built.
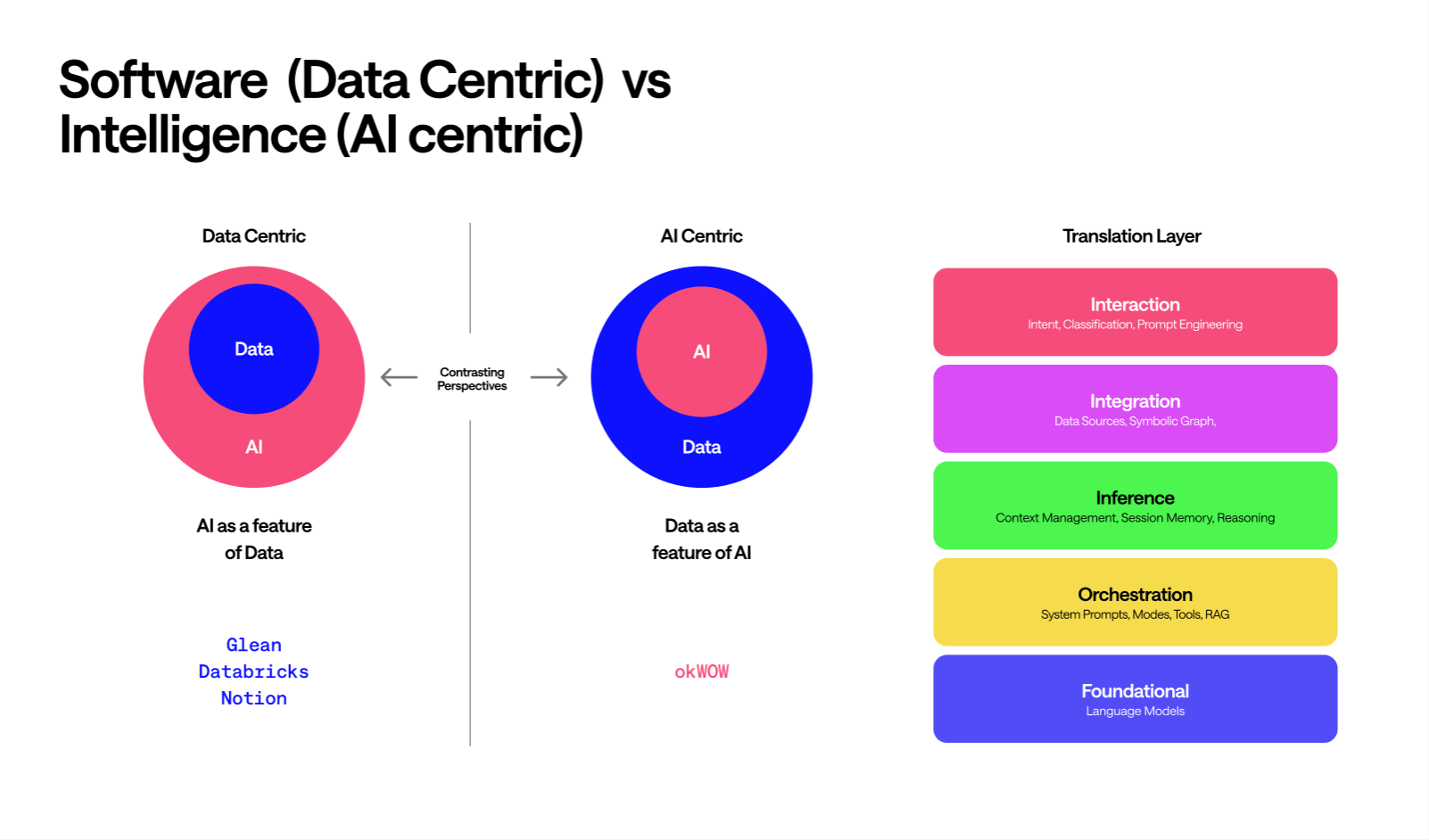
Traditional software is data-centric. Data sits at the center of gravity because everything exists to create, manipulate, and serve it. CRUD is foundational because data is the point. Your CRM, your ERP, and your data warehouse are all systems built around the assumption that data is the primary goal.
AI-native software flips this logic. Intelligence is the point. Data is simply the fuel that the intelligence requires. In this world, data operations become a subcategory of tools. Your CRM, documents, and APIs are merely integrations the AI reaches into when necessary.
In this model, CRUD is no longer a foundational layer; it is a modular capability.
This change dictates the questions we ask. Traditional software asks: “What data do we have and what can we do with it?” AI-native software asks: “What are we trying to accomplish, and what must we access to get there?”
The implications ripple out. Data modeling becomes less central because the intelligence layer can navigate messy, heterogeneous sources. Conversely, the breadth of integrations becomes paramount; the range of what the AI can reach matters more than the depth of any single data model.
This is exactly why many enterprise AI efforts are struggling. Companies like Glean, Databricks, and Notion are bolting intelligence onto data-centric architectures. They treat AI as a feature of data, when the entire center of gravity needs to shift.
Four primitives
If data isn’t foundational, what is?
AI-native systems run on four primitives: Models, Prompts, Context, and Tools. Everything else is composition. Agents, for instance, are simply intentional arrangements of these four.
Models are the reasoning engines. You access them, they’re infrastructure, thats commoditizing fast.
Prompts are the translation layer. How you communicate intent to the model, how you classify and shape its behavior, how you get useful output instead of generic responses. This is where meta-prompting matters: the system figuring out what kind of prompt to construct so users don’t have to.
Context is working memory. What the system knows about this situation, this user, this conversation. Context is doing a lot of what databases used to do for maintaining state and continuity.
Tools are how intelligence touches the world. Reading from systems, writing to systems, taking actions. This is where CRUD lives now, as one capability among many.
Note that data is absent from this list of primitives. It has become a derivative, accessed through Tools only when Context suggests a need, then mediated by Prompts and processed by Models.
Two memory systems
Context alone is insufficient for an organization.
Context is working memory. It lives at the session and conversation level. While context handles the immediate session, organizations need a persistent, compounding layer: Lets call this the knowledge graph.
This represents organizational intelligence. It accumulates in the integration layer, grows denser over time, and encodes relationships that enable judgment.
This graph follows a natural hierarchy: User → Project → Team → Function → Organization. Inheritance and visibility flow through these levels. Your personal context informs your team’s understanding, which rolls up into functional knowledge, which shapes organizational intelligence.
Network effects emerge as more people use it. Every interaction adds signal. Every correction refines the model. The graph gets smarter not because someone built it, but because work flows through it.
This is the difference between a wrapper and a native platform. ChatGPT is a wrapper. It processes your input and forgets. A native platform accumulates organizational intelligence that persists across sessions, users, and projects. The integration layer isn’t plumbing. It’s where proprietary value compounds.
From capture to collaboration
Now we can return to what’s missing from the context graph thesis.
The assumption baked into “capture decision traces” is that agents execute workflows, and the valuable byproduct is a log of what they did. The graph gets built passively, by persisting traces as decisions flow through.
This frames AI as infrastructure. Plumbing that moves data and records the journey.
But the hardest problems in organizations aren’t retrieval problems. They’re judgment problems. Should we prioritize this feature or that one? Is this escalation worth the VP’s time? How do we navigate the tension between what sales wants and what we’re actually building toward? You can’t answer these by querying what happened before. They require synthesizing context, weighing tradeoffs, developing a point of view.
The agents that matter won’t just execute and log. They’ll think alongside humans, participate in decisions, and help people develop better judgment over time.
What that actually looks like
Consider a PM deciding whether to prioritize a feature that sales is pushing hard for, or one that aligns with a longer-term platform bet. No precedent tells you the answer. The context graph might surface that similar trade-offs were made before, but the PM still has to figure out what to do this time, with these constraints, given these stakes.
A thinking partner does more than retrieve data; it engages:
“You’re leaning toward the sales feature. Three similar decisions last year went that way, and two of them created platform debt that’s still dragging on the team. That’s not a reason to decide differently, but it’s worth pressure-testing. What’s different about this one?”
This is collaboration, not a query. The system is helping the PM see the problem more clearly, surface considerations they might miss, develop their own reasoning. The goal isn’t to make the decision for them. It’s to help them make it better, and to get better at making decisions like it.
Over time, this compounds. The PM who uses this system for a year should be a better PM than when they started. Not just a PM with better AI support. A PM with sharper judgment, better instincts, more refined mental models.
Relationships, not just facts
The knowledge graph matters here, but not the way most people talk about it.
A traditional data model asks what entities exist and how they relate formally. A knowledge graph for active intelligence asks what relationships actually matter for reasoning about this situation.
One is schema. The other is understanding.
“Sarah handles mobile design” is a fact. “Sarah handles mobile design, but she’s overloaded right now because she’s covering for James, and when that happens requests should go to Marcus who’s ramping up on the design system” is a relationship structure that enables judgment.
The graph doesn’t just store what happened. It encodes how things connect in ways that support reasoning about what should happen next. And it learns these relationships not through manual entry, but by observing how work actually flows: communication patterns, engagement signals, metadata, what gets routed where, what gets stuck, what moves.
The cold start
A fair question: how do you build organizational intelligence before you have organizational data?
Layered value delivery.
Day one, users get immediate value through conversation modes and interaction quality. The meta-prompting engine, the different thinking styles (collaborative, creative, research, analyst), the ability to have a real thought partner rather than a generic chatbot. This works before the graph has any density.
Meanwhile, the system is transparent about learning. It keeps users in the loop as it builds understanding, asks for feedback, shows its thinking so users can correct. The AI doesn’t pretend to know things it doesn’t. It says “I’m still learning how your team prioritizes. Is this right?”
The user-level graph builds fastest because individual patterns emerge quickly. Personal value comes before organizational value. You get a thinking partner that understands you before you get one that understands your company.
As more people use it, the graph gains density at higher scopes. Team patterns emerge. Functional knowledge accumulates. Organizational intelligence develops. But users aren’t waiting for that. They’re getting value from day one while contributing signal that makes the whole system smarter.
Individual agents, emergent intelligence
The architecture that makes this work isn’t a central brain that knows everything. It’s distributed: every person has their own agent that learns their role, their context, how they work.
When a request comes in, it’s not one system trying to understand the whole organization. It’s agents negotiating with each other. “This seems like a design question. Does your person handle mobile patterns?” “She does, but she’s heads down on the rebrand. Let me check if someone else has bandwidth.”
The routing becomes a conversation between agents who each advocate for their person’s time and attention. That’s closer to how work actually moves through organizations.
And the graph that emerges isn’t a static record of decisions past. It’s a living map of how work actually flows: who collaborates with whom, where information moves versus where it’s supposed to move, which connections are strong, which are bottlenecks. Not because someone documented it, but because it’s a byproduct of agents learning to work together.
What executives actually want
Every executive is trying to answer the same question: what’s actually happening?
The honest answer is usually: we have dashboards and standups and status updates, but nobody really knows. Information gets filtered, delayed, and shaped by the time it reaches the top. The org chart shows reporting lines, not reality.
A system where every agent is learning and connecting creates ground truth as a byproduct. Not because you built a reporting tool, but because work itself flows through agents that are paying attention.
Where are the bottlenecks? Look at where requests pile up. Who are the hidden critical paths? Look at who keeps getting routed even when they’re not the “owner.” Which teams have friction between them? Look at where handoffs fail.
This is the kind of insight consultants charge millions to approximate through interviews and workshops. And it’s always stale by the time they deliver it. A system of learning agents is always current, because the intelligence is generated by the work itself.
Growth as the metric
Here’s a reframe that matters: the goal isn’t efficiency. It’s capability development.
Most AI tools compete on “do this faster” or “automate this task.” That’s a race to the bottom. The moment a competitor offers the same automation cheaper, you lose.
A system oriented around judgment development competes differently. It tracks not just what you know but where you’ve grown. It shows users their thinking evolution over time. Six months ago, you struggled with stakeholder alignment. Here’s how your approach has developed.
This serves multiple purposes. It drives retention because people don’t churn from something that’s actively making them better. It provides a behavioral signal back to the system, helping it understand what’s working. And it makes abstract value tangible for enterprise buyers who need to justify the spend.
The system’s goal isn’t to become invisible. A mature system keeps challenging users rather than letting them coast. The AI that helps you should keep pushing you to level up.
The trust gradient
The obvious question: why would anyone trust an AI with this much organizational influence?
Graduated autonomy.
Observation: The agent builds a map of how work actually moves (not just the official org chart).
Suggestion: “This looks like it belongs to Sarah. Should I route it?” The system learns from your confirmation.
Explanation: The agent routes tasks autonomously but provides a clear “why,” making corrections frictionless.
Integration: The agent becomes part of the team’s fabric, having earned trust through thousands of small, successful interactions.
The key insight: you’re not trusting a central AI with organizational power. You’re trusting your own agent to represent you well. That’s a different kind of relationship.
Why this can’t be bolted on
Incumbents will try to add “AI agents” to their existing platforms. Salesforce is pushing Agentforce. ServiceNow has Now Assist. The pitch is always the same: we have the data, now we add the intelligence.
But they’re playing the wrong game. They’re adding AI as a feature of data. The architecture is still data-centric. The AI is downstream of the database, not the other way around.
Judgment isn’t a feature you add. It develops through ongoing collaboration within a context. An agent that only sees your CRM can’t develop judgment about how your team actually prioritizes. An agent that only activates when you prompt it can’t learn from watching how work flows.
The agents that develop real judgment need to be present continuously, not invoked episodically. They need to see across systems, not within silos. They need to participate in decisions, not just execute them.
That requires starting with intelligence at the center. Data as a feature, not the foundation.
The real opportunity
Everyone’s racing to build the AI that knows everything about your company. Almost no one is building the AI that helps your company get smarter.
That’s the gap. Knowledge compounds when you store it. Judgment compounds when you develop it. One of these is a database with better search. The other is a new kind of organization.
Context graphs will get built. Decision traces will get captured. The infrastructure is coming and it matters. But if all we build is better retrieval, we’ve wasted the moment. The technology finally exists to help people think together, not just search faster. To develop judgment, not just access information.
Without that, AI in the enterprise stays transactional. Query, retrieve, execute. The human provides the judgment, the machine provides the speed. Organizations don’t get smarter. People don’t develop capability. And the hard problems (the ones that actually determine who wins) stay exactly as hard as they were before.
That’s why enterprise AI still feels like autocomplete for knowledge work.
The companies that figure out how to augment capability with AI will have better people, making better decisions, compounding over time. That’s the advantage that can’t be bought or copied. And right now, almost no one is building toward it.